The data were formless like a cloud of tiny birds in the sky
1 Statistical relationships
Most of you will have heard the maxim “correlation does not imply causation”. Just because two variables have a statistical relationship with each other does not mean that one is responsible for the other. For instance, ice cream sales and forest fires are correlated because both occur more often in the summer heat. But there is no causation; you don’t light a patch of the Montana brush on fire when you buy a pint of Haagan-Dazs. - Nate Silver
Correlation is used in many applications and is a basic tool in the data science toolbox. We use it to to describe, and sometimes to test, the relationship between two numeric variables, principally to ask whether there is or is not a relationship between the variables (and if there is, whether they tend to vary positively (both tend to increase in value) or negatively (one tends to decrease as the other increases).
1.1 Objectives
The question of correlation
Data and assumptions
Graphing
Test and alternatives
Practice exercises
2 The question of correlation
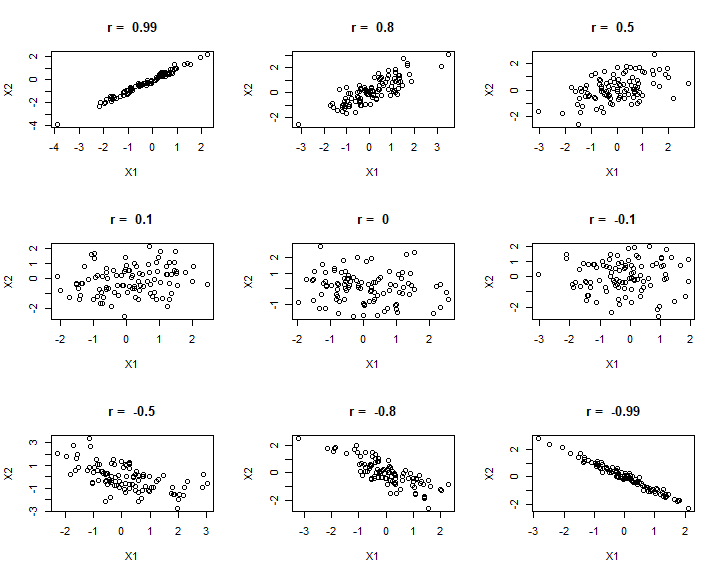
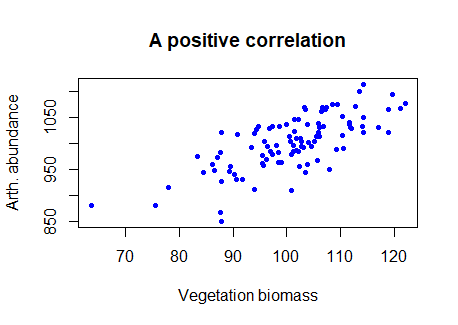
The question of correlation is simply whether there is a demonstrable association between two numeric variables. For example, we might wonder this for two numeric variables, such as a measure of vegetation biomass and a measure of insect abundance. Digging a little deeper, we are interested in seeing and quantifying whether and how the variables may “co-vary” (i.e, exhibit significant covariance). This covariance may be quantified as being either positive or negative and may vary in strength from zero, to perfect positive or negative correlation (+1, or -1). We traditionally visualise correlation with a scatterplot (plot() in R). If there is a relationship, the degree of “scatter” is related to strength of the correlation (more scatter = a weaker correlation).
E.g., we can see in the figure below that the two variables tend to increase with each other positively, suggesting a positive correlation.
“Traditional correlation” is sometimes referred to as the Pearson correlation. The data and assumptions are important for the Pearson correlation - we use this when there is a linear relationship between our variables of interest, and the numeric values are Gaussian distributed.
More technically, the Pearson correlation coefficient is the covariance of two variables, divided by the product of their standard deviations:
{width = “500px”}
The correlation coefficient can be calculated in R using the cor() function.
# Try this:# use veg and arth from above# r the "hard way"# r <- ((covariance of x,y) / (std dev x * std dev y) )# sample covariance (hard way)(cov_veg_arth <-sum( (veg-mean(veg))*(arth-mean(arth))) / (length(veg) -1 ))cov(veg,arth) # easy way# r the "hard way"(r_arth_veg <- cov_veg_arth / (sd(veg) *sd(arth)))# r the easy wayhelp(cor)cor(x = veg, y = arth,method ="pearson") # NB "pearson" is the default method if unspecified
4 Graphing
We can look at a range of different correlation magnitudes, to think about diagnosing correlation.
If we really care and value making a correlation between two specific variables, traditionally we would use the scatterplot like above with the veg and arth data, and the calculation of the correlation coefficient (using plot() and cor() respectively).
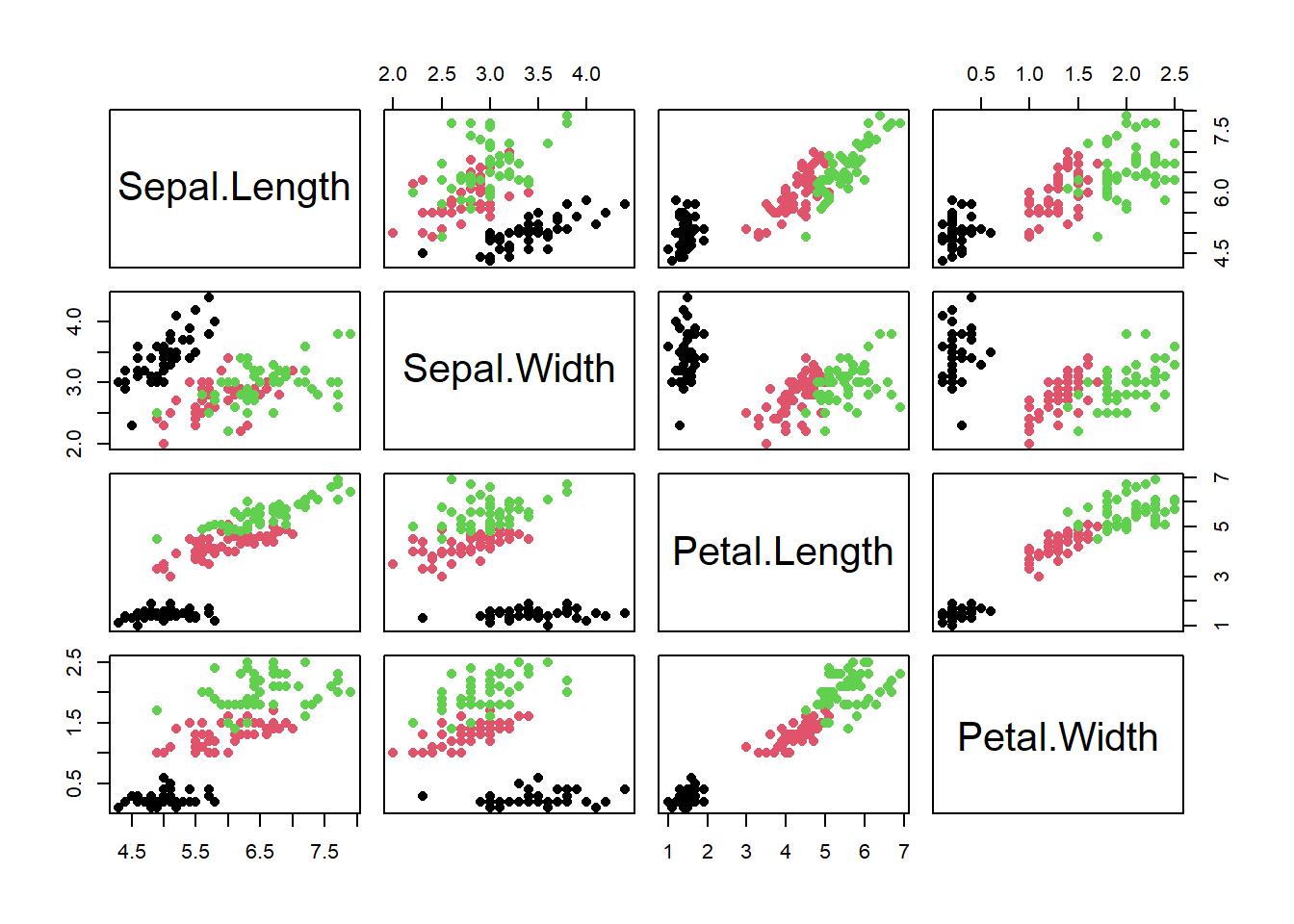
On the other hand, we might have loads of variables and just want to quickly assess the degree of correlation and intercorrelation. To do this we might just make and print a matric of the correlation plot (using pairs()) and the correlation matrix (again using cor())
## Correlation matrices ##### Try this:# Use the iris data to look at correlation matrix # of flower measuresdata(iris)names(iris)
In this case, we can see that the correlation of plant parts is very strongly influenced by species! For further exploration we would definitely want to explore and address that, thus here we have shown how powerful the combination of statistical summary and graphing can be.
5 Test and alternatives
We may want to perform a statistical test to determine whether a correlation coefficient is “significantly” different to zero, using Null Hypothesis Significance Testing. There are a lot of options, but a simple solution is to use the cor.test() function.
An alternative to the Pearson correlation (the traditional correlation, assuming the variables in question are Gaussian), is the Spearman rank correlation, which can be used when the assumptions for the Pearson correlation are not met. We will briefly perform both tests.
Let’s try a statistical test of correlation. We need to keep in mind an order of operation for statistical analysis, e.g.:
1 Question
2 Graph
3 Test
4 Validate (e.g. test assumptions)
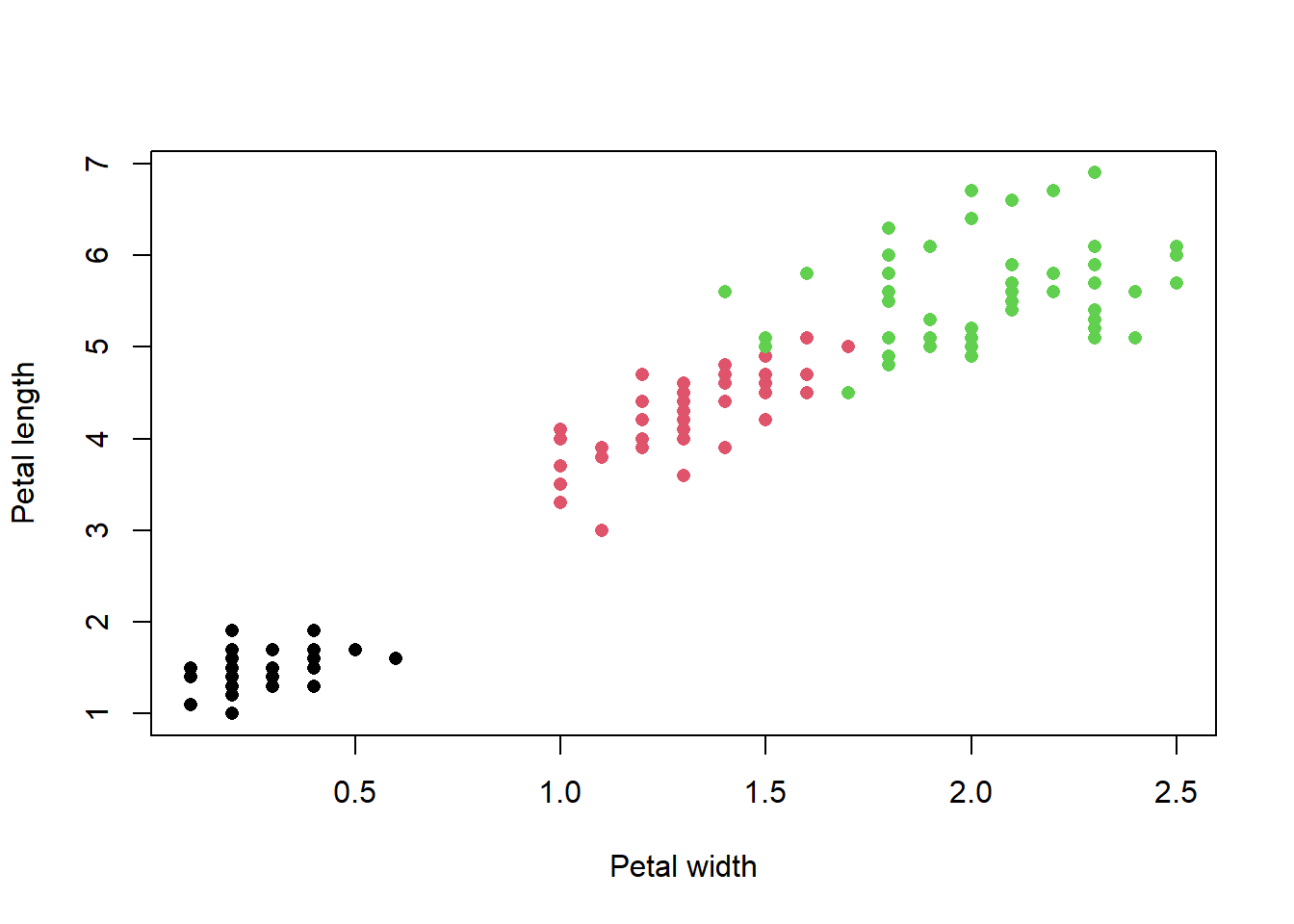
## Correlation test ##### Try this:# 1 Question: whether Petal length and width are correlated?# (i.e. is there evidence the correlation coefficient different to zero)
Pearson's product-moment correlation
data: iris$Petal.Width and iris$Petal.Length
t = 43.387, df = 148, p-value < 2.2e-16
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.9490525 0.9729853
sample estimates:
cor
0.9628654
6 Note about results and reporting
When we do report or document the results of an analysis we may do it in different ways depending on the intended audience.
6.1 Documenting results only for ourselves (almost never)
It would be typical to just comment the R script and have your script and data file in fully reproducible format. This format would also work for close colleague (who also use R), or collaborators, to use to share or develop the analysis. Even in this format, care should be taken to
clean up redundant or unnecessary code
to organize the script as much as possible in a logical way, e.g. by pairing graphs with relevant analysis outputs
removing analyses that were tried but obsolete (e.g. because a better analysis was found)
6.2 Documenting results to summarize to others (most common)
Here it would be typical to summarize and format output results and figures in a way that is most easy to consume for the intended audience.
You should NEVER PRESENT RAW COPIED AND PASTED STATISTICAL RESULTS (O.M.G.!).
- Ed Harris
A good way to do this would be to use R Markdown to format your script to produce an attractive summary, in html, MS Word, or pdf formats (amongst others).
Second best (primarily because it is more work and harder to edit or update) would be to format results in word processed document (like pdf, Word, etc.). This is the way most scientists tend to work.
6.3 Statistical summary
Most statistical tests under NHST will have exactly three quantities reported for each test:
the test statistic (different for each test, r (“little ‘r’”) for the Pearson correlation)
the sample size or degrees of freedom
the p-value.
For our results above, it might be something like:
We found a significant correlation between petal width and length (Pearson’s r = 0.96, df = 148, P < 0.0001)
NB:
the rounding of decimal accuracy (usually 2 decimals accuracy, if not be consistent)
the formatting of the p-value (if smaller than 0.0001 ALWAYS use P < 0.0001; also never report the P value in scientific notation).
The 95% confidence interval of the estimate of r is also produced (remember, we are making an inference on the greater population from which our sample was drawn), and we might also report that in our descriptive summary of results, if it is deemed important.
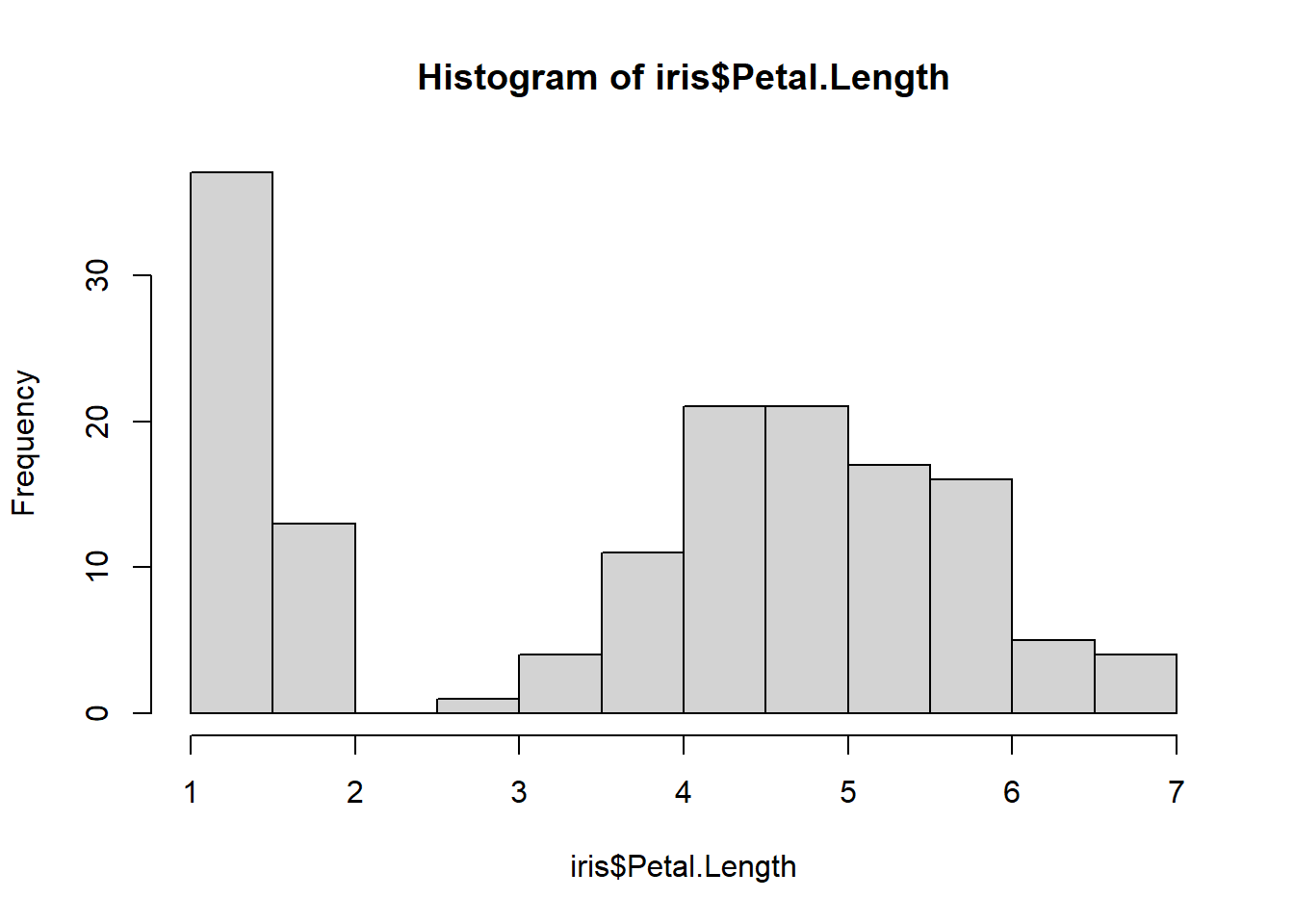
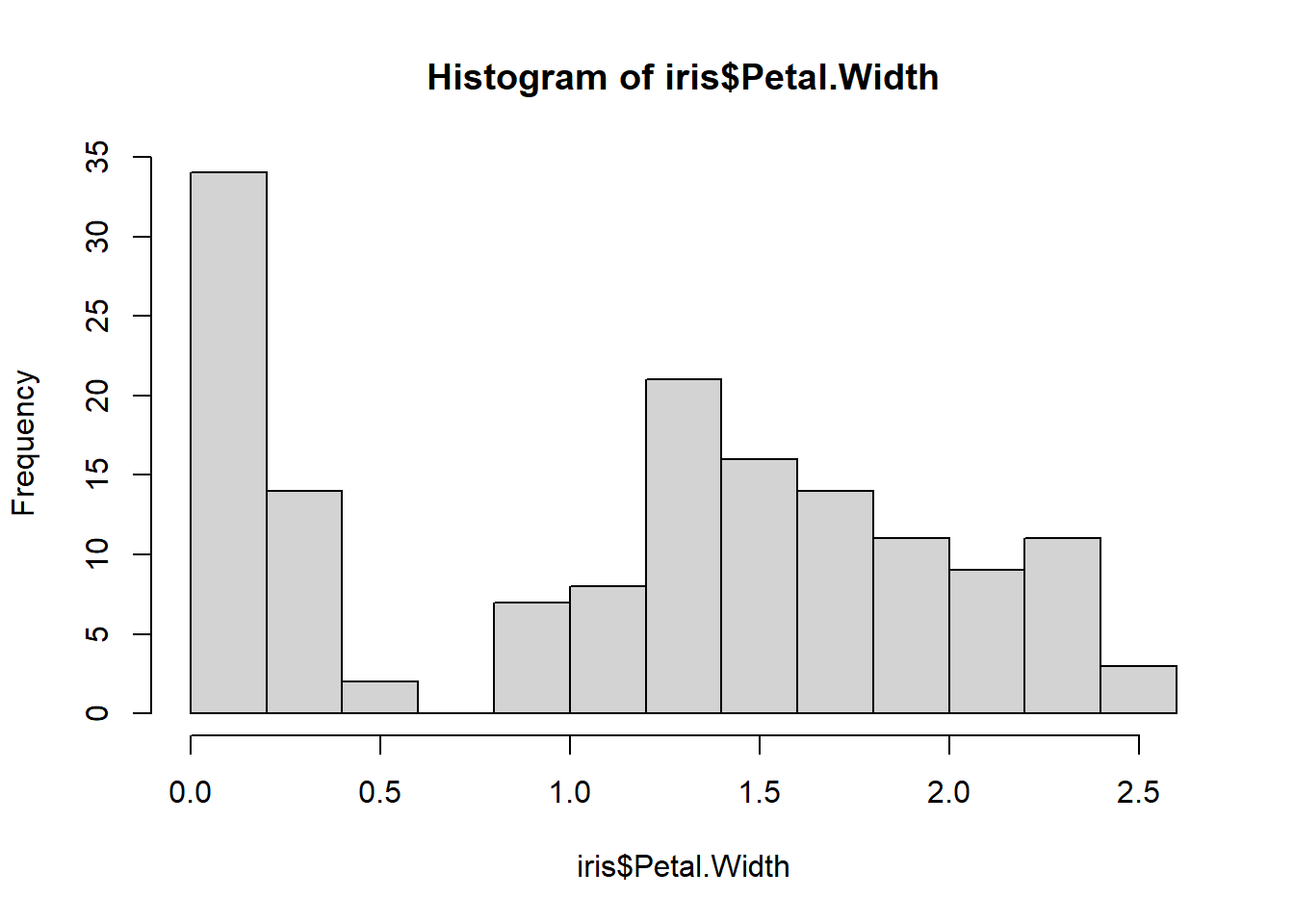
# 4 Validatehist(iris$Petal.Length) # Ummm..
hist(iris$Petal.Width) # Yuck
# We violate the assumption of Gaussian# ... Relatedly, we also violate the assumption of independence # due to similarities within and differences between species!
6.4 Flash challenge
Write a script following the steps to question, graph, test, and validate for each iris species separately. Do these test validate? How does the estimate of correlation compare amongst the species?
6.5 Correlation alternatives to Pearson’s
There are several alternative correlation estimate frameworks to the Pearson’s; we will briefly look at the application of the Spearman correlation. The main difference is a relaxation of assumptions. Here the main assumptions are that:
The data are ranked or otherwise ordered
The data rows are independent
Hence, the Spearman rank correlation descriptive coefficient and test are appropriate even if the data are not “bivariate” Gaussian (this just means both variables are Gaussian) or if the data are not strictly linear in their relationship.
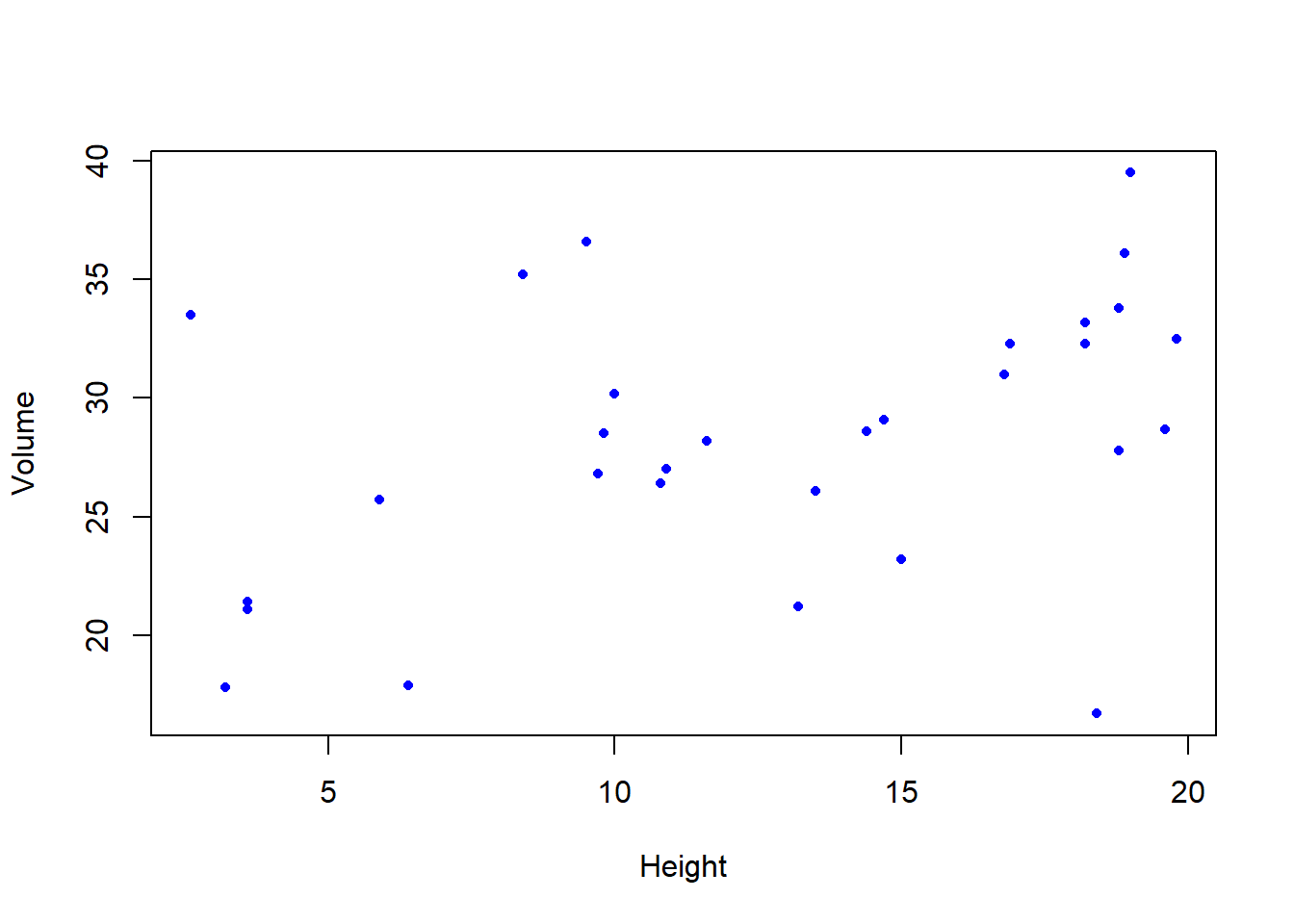
Warning in cor.test.default(height, vol, method = "spearman"): Cannot compute
exact p-value with ties
Spearman's rank correlation rho
data: height and vol
S = 2721.7, p-value = 0.03098
alternative hypothesis: true rho is not equal to 0
sample estimates:
rho
0.3945026
NB the correlation coefficient for the Spearman rank correlation is notated as “rho” (the Greek letter \(\rho\) - sometimes avoided by non-math folks because it looks like the letter “p”), reported and interpreted exactly like the Pearson correlation coefficient, r.
Load the waders data and read the help page. Use the pairs function on the data and make a statement about the overall degree of intercorrelation between variables based on the graphical output.
7.2
Think about the variables and data themselves in waders. Do you expect the data to be Gaussian? Formulate hypothesis statements for correlations amongst the first 3 columns of bird species in the dataset. Show the code to make three good graphs (i.e., one for each pairwise comparison for the first three columns), and perform the three correlation tests.
7.3
Validate the test performed in question 2. Which form of correlation was performed, and why. Show the code for any diagnostic tests performed, and any adjustment to the analysis required. Formally report the results of your validated results.
7.4
Load the 2.3-cfseal.xlsx data and examine the information in the data dictionary. Analyse the correlations amongst the weight, heart, and lung variables, utilizing the 1 question, 2 graph, 3 test and 4 validate workflow. Show your code and briefly report the results.
7.5
Comment on the expectation of Gaussian for the age variable in the cfseal data. Would expect this variable to be Gaussian? Briefly explain you answer and analyse the correlation between weight and age, using our four-step workflow and briefly report your results.
7.6
Write a plausible practice question involving any aspect of the use of correlation, and our workflow. Make use of the data from either the waders data, or else the cfseal data.

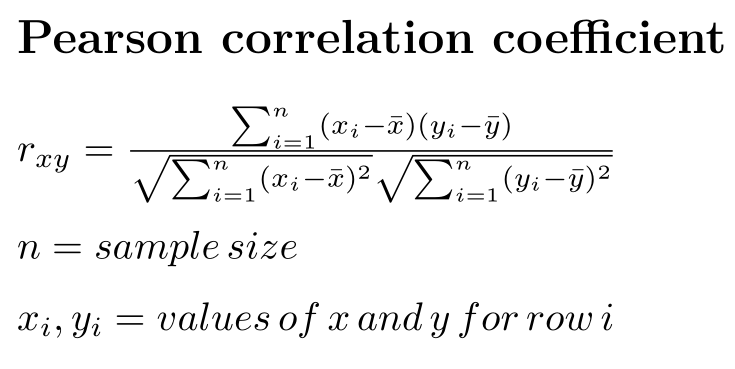 {width = “500px”}
{width = “500px”}